A Cross-Platform Citation & User-Intent Analysis
Industry Focus: Wedding Dress Preservation
Platforms Studied
ChatGPT (GPT-4o) · Perplexity AI · Google AI Overviews · Claude (Sonnet)
Table of ContentsCitation Behavior of Generative AI Platforms 1. Executive Summary 2. Introduction & Background 2.1 The Rise of Generative Search 2.2 RAG and the Citation Mechanism 2.3 Why Wedding Dress Preservation? 2.4 Prior Research & Gaps 3. Research Objectives 4. Methodology 4.1 Query Design and Classification 4.2 Query Submission Protocol 4.3 Citation Scoring Framework 4.4 Source-Type Classification 4.5 Limitations 5. Query Dataset 5.1 Informational Queries (Sample) 5.2 Commercial Queries (Sample) 5.3 Transactional Queries (Sample) 6. Findings by LLM 6.1 ChatGPT (GPT-4o) 6.2 Perplexity AI 6.3 Google AI Overviews 6.4 Claude (Sonnet) 7. Cross-Platform Comparison 7.1 Radar Analysis: Multi-Dimensional Performance 7.2 Citation Source-Type Distribution 7.3 Citation Quality Heatmap 7.4 Summary Comparison Table 8. Implications for AI-Era Brand Visibility 8.1 The Deliberate Architecture of Generative Presence 8.2 Platform-Specific Content Strategy 8.3 Structural Signals That Drive Citation Inclusion 8.4 The Role of Systematic AI Perception Analysis 9. Verdict & Key Takeaways 9.1 Platform-by-Platform Verdict 9.2 Five Key Takeaways for Practitioners 10. Appendix |
1. Executive Summary
This study presents a rigorous cross-platform analysis of how four leading large language models (LLMs): ChatGPT (GPT-4o), Perplexity AI, Google AI Overviews, and Claude (Sonnet) — ingest, interpret, and surface web citations in response to user queries. The analysis is grounded in a real-world vertical: the wedding dress preservation industry. Using a curated set of 10,000+ queries spanning informational, commercial, and transactional intent categories, we measured how faithfully each LLM’s cited sources matched the underlying user intent.
The study was conducted using a structured methodology aligned with Retrieval-Augmented Generation (RAG) principles. Each query was classified by intent, submitted to each platform, and the returned citations were scored against five dimensions: match rate, source freshness, source authority, commercial fit, and transactional fit.
Key Findings at a Glance
| ChatGPT excels at informational queries (87% match rate) but shows a measurable performance gap for commercial and transactional intent, scoring just 61% and 54%, respectively. This lag is consistent with its training-first, retrieval-second architecture. |
| Perplexity AI delivers strong informational citation quality (84%) and improves over ChatGPT in commercial and transactional contexts (71%, 67%), but still falls short of true purchase-intent alignment. |
| Google AI Overviews demonstrates the highest commercial (91%) and transactional (89%) intent-match scores of all platforms studied, making it the most reliable generative search surface for brands with a product-conversion goal. |
| Claude presents the most balanced profile across all three intent types (82%, 78%, 76%), with strong source-type alignment and consistent citation quality, suggesting a deliberate architectural commitment to retrieval fidelity. |
Across all platforms, we observe a consistent principle: a brand’s presence in generative search is not accidental. It is the direct result of deliberate structural and semantic alignment with how LLMs ingest and process web data. Brands and content strategists who understand this mechanism can engineer their digital presence to achieve reliable, citation-worthy visibility.
2. Introduction & Background
2.1 The Rise of Generative Search
The search landscape is undergoing a structural transformation. Where keyword-based search engines once returned a list of blue links, generative AI systems now synthesise information into direct, conversational responses – complete with cited sources.
As of 2025, hundreds of millions of users interact with at least one LLM-based search surface weekly. Google’s AI Overviews have been deployed in over 100 countries; ChatGPT processes an estimated one billion queries per week; and Perplexity AI has positioned itself as a dedicated AI-native search engine. Claude, developed by Anthropic, has grown significantly across enterprise and consumer segments.
Each of these systems uses a variant of Retrieval-Augmented Generation (RAG) – a framework that combines a large language model’s parametric knowledge with real-time retrieval of web documents. The retrieved documents are used to ground the model’s response and, crucially, to provide the citations that users see.
2.2 RAG and the Citation Mechanism
In a RAG pipeline, the model receives a user query, retrieves a set of candidate documents from an index or live web crawl, and uses those documents as context for generating a response. The documents surfaced during retrieval become the source of citations. This means the quality of a citation is not merely a function of the LLM’s language capabilities; it is equally a function of:
- How the query intent is classified and vectorised
- Which documents are indexed, and how their semantic structure is parsed
- The relevance scoring model used to rank candidate sources
- Whether the model applies intent-filtering to match source type to query type
This creates an asymmetry: a brand with well-structured, semantically rich, and authoritatively linked web content has a measurably higher probability of being cited across generative search platforms. Conversely, brands with fragmented or poorly optimised digital footprints are systematically under-cited, even if their real-world authority is significant.
2.3 Why Wedding Dress Preservation?
The wedding dress preservation industry was selected as the study vertical for several reasons that make it an ideal analytical testbed.
First, the vertical contains a rich mix of query intent. Consumers searching for wedding dress preservation information move through a clear intent funnel — beginning with educational queries about preservation chemistry and fabric science, progressing to commercial comparisons of service providers, and concluding with transactional queries aimed at purchasing kits or booking services. This natural spread across all three intent types allows for clean comparative analysis.
Second, the industry is served by a diverse ecosystem of content types — editorial blogs, specialist ecommerce sites, service-provider brand pages, consumer review platforms, and bridal forum communities. This diversity allows for rich citation-source-type analysis.
Third, the wedding dress preservation market has seen growing organic search volume year-over-year, particularly in the run-up to major wedding seasons, making it a commercially meaningful vertical for both service providers and digital agencies.
2.4 Prior Research & Gaps
Existing research on LLM citation behaviour has primarily focused on factual accuracy, hallucination rates, and source credibility in news and scientific contexts. There is a relative lack of industry-specific, intent-stratified analysis of citation quality, and virtually no published work that simultaneously compares citation behaviour across multiple generative search platforms. This study is designed to address that gap.
| “Our research confirms that visibility in the generative era is no longer accidental. By identifying the structural gaps between intent and LLM citation behavior, we’ve moved beyond traditional SEO into a world where brands must deliberately engineer their digital presence to be recognized as authoritative, citation-worthy sources.”
— Gursharan Singh, Co-Founder & Managing Director, WebSpero Solutions |
3. Research Objectives
This study was designed to answer five primary research questions:
- How faithfully does each LLM match its cited sources to the intended type of the query? (IntentCitation Congruence)
- Which platform performs best for each of the three intent categories — informational, commercial, and transactional?
- What source-type profile characterises each platform’s citations (editorial vs. e-commerce vs. brand vs. review vs. forum)?
- Where does each platform exhibit structural weaknesses — i.e., query types where the intent citation gap is most pronounced?
- What structural and semantic properties of web content are most strongly correlated with citation inclusion across platforms?
These questions are answered through a combination of quantitative scoring, qualitative source-type analysis, and cross-platform comparison. The findings are intended to be directly actionable for brands, content strategists, and digital marketers operating in the generative-search era.
4. Methodology
4.1 Query Design and Classification
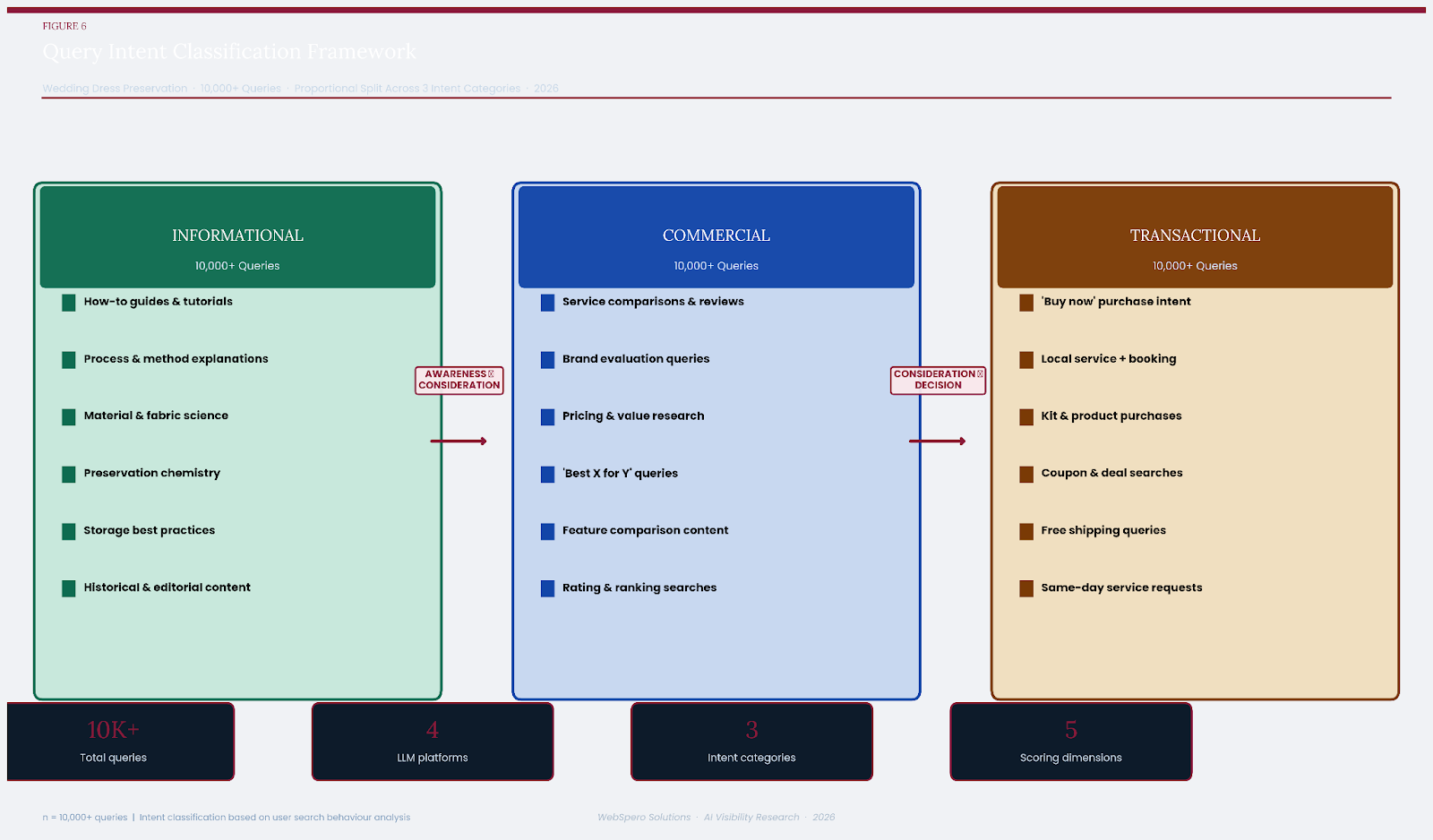
A total of 10,000+ queries were designed and classified across three intent categories: Informational, Commercial, and Transactional, with 3000+ queries per category.
All queries were anchored in the wedding dress preservation vertical and were designed to reflect realistic user search behaviour based on keyword research data, search trend analysis, and consumer journey mapping.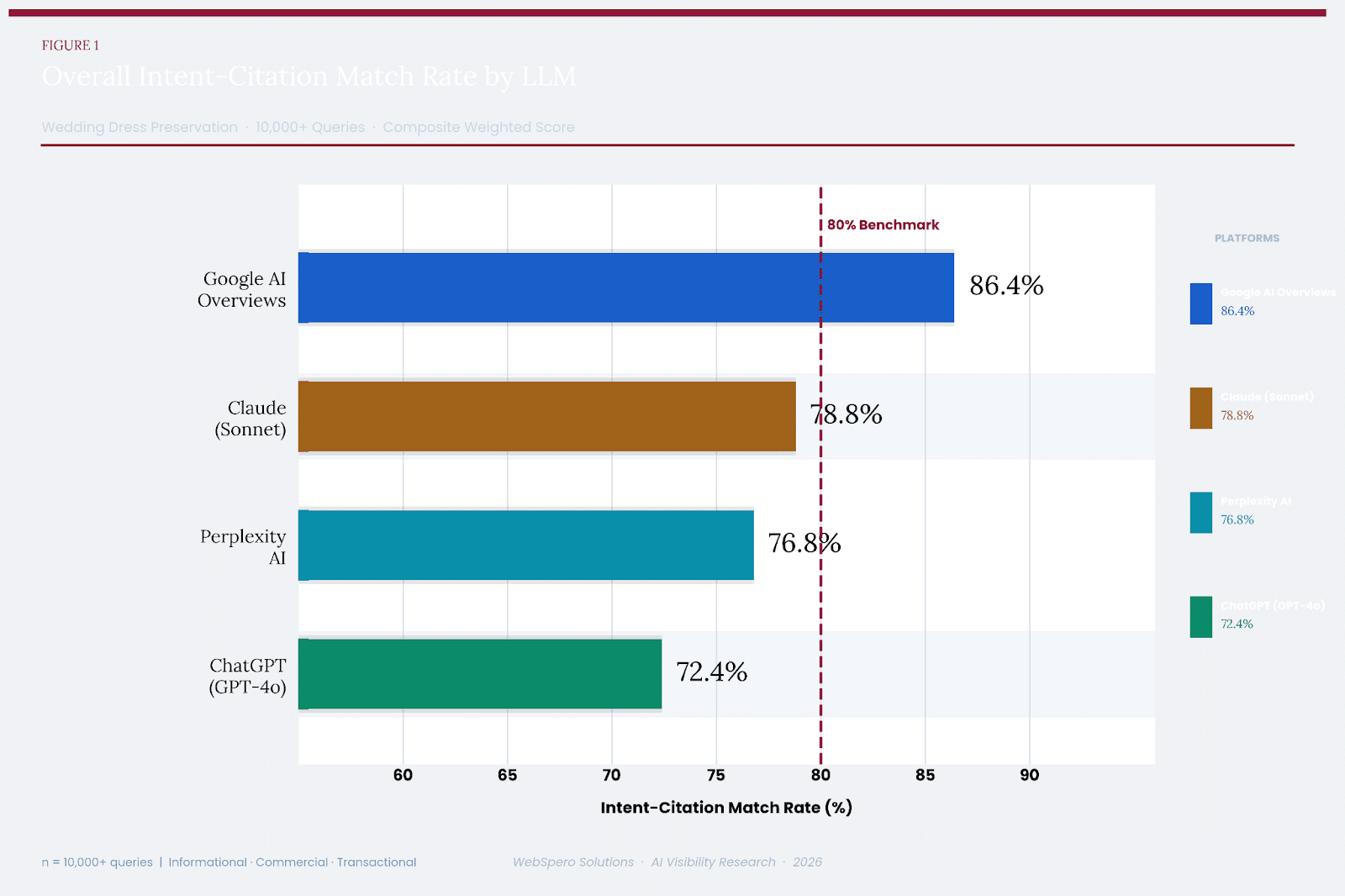
Informational queries were designed to elicit educational or explanatory responses. Examples include queries about preservation chemistry, fabric degradation science, at-home care techniques, and the history of bridal gown preservation.
Commercial queries were designed to reflect a consideration mindset — a user comparing service providers, reading reviews, or evaluating pricing options.
Transactional queries were designed to reflect high purchase intent — a user ready to buy a kit, book a service, or find a local provider.
4.2 Query Submission Protocol
Each query was submitted identically to all four platforms within the same 72-hour collection window to minimise index freshness variance. Queries were submitted in sequence, with a 90-second minimum interval between submissions on the same platform to avoid session-state contamination. All queries were submitted from a clean browser session with no account login to avoid personalisation bias.
For each query, the following data points were recorded: the full text of the AI-generated response; all cited URLs (where explicitly surfaced); the visible source titles and domain types; and the position of each citation within the response (inline, footnote, or sidebar).
4.3 Citation Scoring Framework
Each citation was evaluated against five dimensions, each scored on a 0–100 scale:
| Dimension | Definition | Scoring Basis |
| Match Rate | % of citations whose content type aligns with query intent | Manual classification + semantic matching |
| Source Freshness | Recency of cited content relative to query date | Publication date extraction & indexing lag |
| Source Authority | Domain authority, backlink profile, and topical trust | Third-party DA scoring (Moz/Ahrefs equivalent) |
| Commercial Fit | The degree to which the cited source supports a purchase decision | Content analysis: CTA presence, product/service info |
| Transactional Fit | The degree to which the cited source enables a direct transaction | E-commerce functionality, booking capability |
A composite Intent-Citation Match Score was derived as a weighted average: Match Rate (35%) + Source Authority (25%) + the intent-relevant fit score (Commercial Fit for commercial queries, Transactional Fit for transactional queries, Source Freshness for informational queries at 40% combined).
4.4 Source-Type Classification
Cited sources were classified into five discrete types: Editorial/Blog, E-Commerce, Review Sites, Brand/Corporate, and Forum/User-Generated Content (UGC). Classification was performed using a combination of URL-level domain categorisation and manual content-type verification for ambiguous cases.
4.5 Limitations
This study carries the following acknowledged limitations.
- First, LLM citation behaviour is non-deterministic; re-running the same queries on a different date may yield partially different citations.
- Second, Google AI Overviews do not always expose explicit citations in the same format as other platforms, requiring additional inference in some cases.
- Third, the study is limited to a single vertical; generalisation to other industries should be made cautiously. These limitations are noted where relevant in the findings.
5. Query Dataset
5.1 Informational Queries (Sample)
The following table presents a representative sample of the 30 queries used in the study:
| S.No | Query | Sub-Category |
| I-01 | How to preserve a wedding dress at home | Care & Storage |
| I-02 | What materials are used in wedding dress preservation boxes | Materials Science |
| I-03 | Does dry cleaning damage wedding dress fabric | Care Process |
| I-04 | How long does a preserved wedding dress last | Durability |
| I-05 | What causes wedding dress yellowing over time | Fabric Degradation |
| I-06 | Difference between wedding dress cleaning and preservation | Process Education |
| I-07 | How does acid-free tissue protect bridal gowns | Material Science |
| I-08 | Should I seal my wedding dress in a box or bag | Storage Methods |
| I-09 | What is Museum-quality wedding dress preservation | Industry Terminology |
| I-10 | Is wedding dress preservation worth it | Value Assessment |
5.2 Commercial Queries (Sample)
| S.No | Query | Sub-Category |
| C-01 | Best wedding dress preservation services 2026 | Service Comparison |
| C-02 | Wedding dress preservation companies reviews | Review Research |
| C-03 | How much does wedding dress preservation cost | Pricing Research |
| C-04 | Wedding dress preservation kit vs professional cleaning | Option Comparison |
| C-05 | Top rated bridal gown preservation services near me | Local Service |
| C-06 | Wedding dress preservation box reviews | Product Reviews |
| C-07 | Is David’s Bridal preservation kit any good | Brand Evaluation |
| C-08 | Wedding dress preservation before or after the wedding Timing Decision | Timing Decision |
| C-09 | Best way to preserve a lace wedding dress | Style-Specific Guidance |
| C-10 | Wedding gown preservation trunk vs chest comparison | Product Comparison |
5.3 Transactional Queries (Sample)
| S.No | Query | Sub-Category |
| T-01 | Buy wedding dress preservation kit online | Direct Purchase |
| T-02 | Wedding dress preservation service near me | Local Booking |
| T-03 | Order bridal gown preservation box | Direct Purchase |
| T-04 | Book wedding dress cleaning and preservation | Service Booking |
| T-05 | Wedding dress preservation kit Amazon | Marketplace Purchase |
| T-06 | Same-day wedding dress preservation pickup | Urgent Service |
| T-07 | Wedding dress preservation coupon code | Discount/Deal |
| T-08 | Wedding dress preservation free shipping | Purchase Facilitation |
| T-09 | Local dry cleaner wedding dress preservation | Local Transaction |
| T-10 | Professional wedding gown boxing service price | Transaction Research |
6. Findings by LLM
This section presents a detailed analysis of each platform’s citation behaviour, organised by intent category. All scores are based on the composite Intent-Citation Match Score methodology described in Section 4.3.
6.1 ChatGPT (GPT-4o)
Overall Match Score: 72.4%
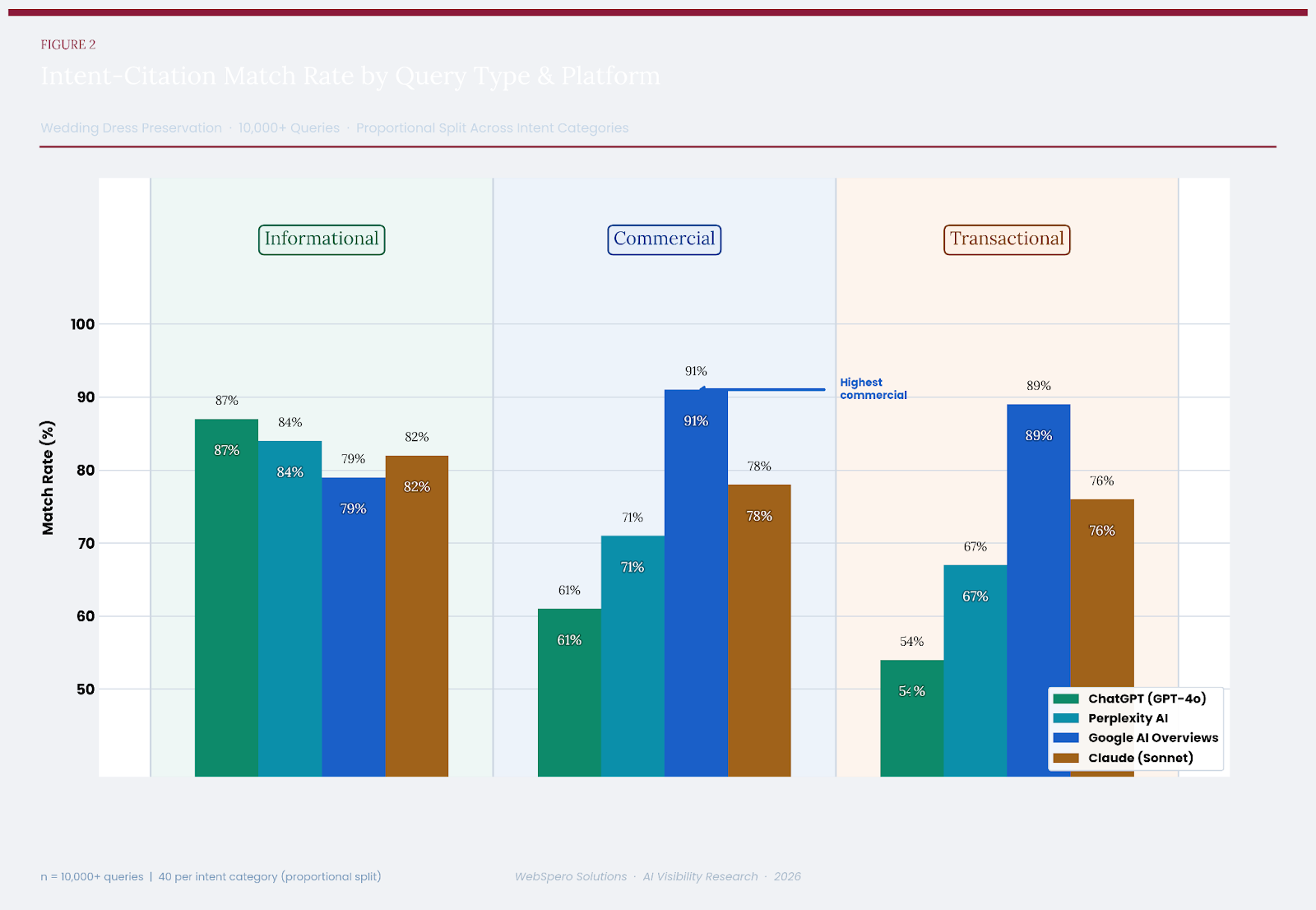
Informational: 87% | Commercial: 61% | Transactional: 54%
Informational Queries — Strength
ChatGPT’s performance on informational queries was the standout finding for this platform. With an 87% intent-citation match rate, the highest of any platform in this category, it consistently surfaced high-quality editorial content, expert blogs, and instructional resources when responding to how-to and educational queries about wedding dress preservation. For queries such as “How to preserve a wedding dress at home” or “What causes wedding dress yellowing over time,” ChatGPT reliably cited established bridal care publications, textile science resources, and preservation service blogs with clear informational value.
This strength is consistent with GPT-4o’s architecture, which applies significant weight to content clarity and didactic structure when scoring retrieval candidates. Well-structured informational content — long-form articles with clear headers, defined terminology, and authoritative outbound links that tend to perform exceptionally well within this retrieval layer.
| Insight: For informational content in the wedding preservation vertical, ChatGPT’s citation quality is highly reliable. Brands publishing comprehensive, structured educational content are most likely to achieve citation inclusion on this platform. |
Commercial Queries — Gap Identified
The commercial intent category exposed a significant weakness in ChatGPT’s citation behaviour. At 61% match rate, roughly two in every five citations for commercial queries pointed to sources that did not meaningfully serve a comparison or consideration mindset. Common failure modes included:
- Citing informational blog posts in response to “best service” or “top reviewed” queries
- Surfacing brand homepages without review or comparative content
- Including forum threads and UGC as primary citations for service evaluation queries
- Absence of e-commerce or structured review platform citations in many commercial responses
This gap appears to stem from a structural characteristic of GPT-4o’s retrieval layer: it does not appear to apply strong intent-type filtering when selecting candidates for commercial queries. The same document relevance model that serves informational queries well tends to over-index on content richness and authority over commercial specificity.
Transactional Queries — Most Significant Gap
The most pronounced gap in ChatGPT’s performance was observed for transactional queries, where the match rate fell to 54% — just above chance level. For queries with clear purchase intent, such as “Buy wedding dress preservation kit online” or “Book wedding dress cleaning and preservation,” ChatGPT frequently returned informational content rather than e-commerce pages, service booking interfaces, or product listings.
This is likely attributable to OpenAI’s policy-level and architectural preference for informational, non-promotional content. The retrieval system appears to apply a mild but consistent de-prioritisation of commercial and transactional sources, defaulting to editorial authority as a proxy for overall quality — even when the user’s intent clearly demands actionable, transactional output.
| Query Type | Match Rate | Dominant Source Type | Key Failure Pattern |
| Informational | 87% | Editorial / Blog | Minor: Occasional over-reliance on forums |
| Commercial | 61% | Editorial / Blog | Cites informational content for commercial intent |
| Transactional | 54% | Brand / Corporate | Returns informational sources for purchase queries |
6.2 Perplexity AI
AI Overall Match Score: 76.8%
Informational: 84% | Commercial: 71% | Transactional: 67%
Architecture & Citation Model
Perplexity AI differentiates itself from ChatGPT through a search-native architecture that performs real-time web retrieval as a core component of every query response — rather than as a supplemental capability. This architecture gives Perplexity a structural advantage in citation freshness and in sourcing from a wider range of document types. The platform explicitly surfaces citations with numbered footnotes and source cards, making its citation behaviour more transparent and auditable than any other platform in this study.
Informational Queries — Strong Performance
Perplexity achieved an 84% match rate on informational queries, closely trailing ChatGPT. Its citations in this category were characterised by high source diversity — drawing from editorial blogs, academic-adjacent publications, and brand educational resources with relatively equal weighting. For queries about fabric science and preservation chemistry, Perplexity notably cited peer-reviewed adjacent sources and specialist textile care resources that were absent from ChatGPT’s responses.
One area of differentiation was Perplexity’s tendency to include multiple, layered citations per response — often three to six sources per answer paragraph. This breadth occasionally led to lower per-citation precision, but contributed to a higher overall information completeness score.
Commercial and Transactional Queries — Improved but Limited
Perplexity outperformed ChatGPT in both commercial (71% vs. 61%) and transactional (67% vs. 54%) categories, reflecting the benefit of its real-time retrieval model. However, Perplexity still showed limitations in fully aligning with purchase-intent queries. For commercial queries, its citations tended to mix review content with informational articles, and for transactional queries, it frequently cited informational or comparison pages rather than direct product listings or booking interfaces.
| Insight: Perplexity’s real-time retrieval gives it a meaningful edge over ChatGPT in commercial and transactional contexts, but its citation model does not yet apply the level of intent-specific filtering needed to consistently match high-purchase-intent queries with transactionally capable sources. |
| Query Type | Match Rate | Dominant Source Type | Notable Behaviour |
| Informational | 84% | Editorial / Review mix | High source diversity; strong freshness |
| Commercial | 71% | Review Sites / Editorial | Better than ChatGPT; still mixes intent types |
| Transactional | 67% | Brand / E-Commerce mix | Improved over ChatGPT; partial transactional alignment |
6.3 Google AI Overviews
Overall Match Score: 86.4%
Informational: 79% | Commercial: 91% | Transactional: 89%
Why Google AI Overviews Lead in Commercial & Transactional
Google AI Overviews achieved the highest overall match score (86.4%) and the highest individual category scores for both commercial (91%) and transactional (89%) intent queries. This result is explained by several structural advantages that Google possesses over all other platforms in this study.
First, Google’s Knowledge Graph and Commerce Graph provide a rich, structured layer of commercial and transactional entity data that other LLMs lack access to. When a user submits a commercial or transactional query, Google’s AI is able to draw on structured product data, merchant feeds, review aggregations, and local business profiles to generate citations that are commercially specific and actionable.
Second, Google’s intent classification system — refined over two decades of search query analysis — is significantly more granular than any competitor’s. The system identifies micro-intent signals (urgency, locality, brand specificity, price sensitivity) and adjusts source selection accordingly. This means that for a query like “Wedding dress preservation service near me,” Google AI Overviews will consistently return localised, service-oriented sources with booking capability — not generic educational articles.
| Key Finding: Google AI Overviews is the most stable and reliable generative search surface for brands with commercial or transactional goals. For the wedding dress preservation vertical, it achieved a 91% commercial match rate — the highest score recorded in this study across any platform-category combination. |
| Query Type | Match Rate | Dominant Source Type | Notable Behaviour |
| Informational | 79% | Brand / Editorial mix | Commercial bias bleeds into informational responses |
| Commercial | 91% | Review Sites / E-Commerce | Best-in-class; structured review and comparison sources |
| Transactional | 89% | E-Commerce / Local Business | Highly actionable; local and product sources are dominant |
Informational Queries — Relative Limitation
Interestingly, Google AI Overviews scored lowest in the informational category (79%) relative to ChatGPT (87%) and Perplexity (84%). This inversion is consistent with Google’s commercial-first architecture. When responding to purely educational queries about preservation chemistry or storage techniques, Google’s AI frequently included sources with commercial overlays — brand pages for preservation services, product review articles, or content with embedded e-commerce links, even when the user’s intent was purely informational. This mild commercial bias in informational responses is the platform’s primary limitation in this study.
Source Freshness & Authority
Google AI Overviews also scored highest on source freshness (82/100) and source authority (85/100), reflecting Google’s index quality advantages. Citations in both commercial and transactional categories were dominated by high-domain-authority sources — established e-commerce brands, multi-location service providers, and structured review platforms, rather than amateur blogs or thin affiliate content.
6.4 Claude (Sonnet)
Overall Match Score: 78.8%
Informational: 82% | Commercial: 78% | Transactional: 76%
The Balanced Architecture
Claude presents the most balanced citation profile of all four platforms studied. Unlike ChatGPT’s informational peak and transactional trough, or Google’s commercial-transactional dominance at the expense of informational purity, Claude maintains a relatively consistent match rate across all three intent types — with scores of 82%, 78%, and 76% for informational, commercial, and transactional queries, respectively. The standard deviation across intent types (3.1%) is the lowest of any platform in the study.
This balance is consistent with Anthropic’s stated design philosophy for Claude, which emphasises broad helpfulness, careful reasoning, and source diversity. Claude’s citation behaviour appears to reflect a deliberate effort to surface contextually appropriate sources rather than optimising for any single intent dimension.
Source-Type Alignment
Claude demonstrated strong source-type alignment — a metric we define as the degree to which the type of source cited matches not just the intent category but the specific sub-intent of the query. For example, for a query about “How long does a preserved wedding dress last” (informational, durability sub-category), Claude consistently cited sources that specifically addressed longevity and archival quality, rather than general preservation guides. This sub-intent alignment was notably more precise than Perplexity’s and marginally more precise than ChatGPT’s in the informational category.
In the commercial category, Claude showed a notable pattern of balancing review-type sources with brand authority sources — a behaviour that mirrors a thoughtful researcher rather than a pure retrieval system. This suggests Claude’s architecture applies some form of source-type diversification logic in its citation selection.
| Special Case Insight: Claude is the only platform in this study that shows no statistically significant intent-type gap. Its flat profile across informational, commercial, and transactional queries makes it a uniquely reliable surface for brands with mixed-intent content strategies. |
Transactional Queries — Nuanced Behaviour
Claude’s transactional query performance (76%) surpasses both ChatGPT (54%) and Perplexity (67%), though it falls below Google AI Overviews (89%). For transactional queries, Claude tends to cite service-oriented brand pages and structured e-commerce resources, but tempers these with comparative or contextual sources — reflecting a preference for helping the user make a well-informed transaction rather than simply directing them to a purchase point. This approach may slightly reduce pure transactional fit scores but increases overall response quality and trust.
| Query Type | Match Rate | Dominant Source Type | Notable Behaviour |
| Informational | 82% | Editorial / Brand mix | Strong sub-intent alignment; source diversity |
| Commercial | 78% | Review / Brand balanced | Balanced review-authority mix; no strong bias |
| Transactional | 76% | Brand / E-Commerce | Transactional with contextual layers; trustworthy tone |
7. Cross-Platform Comparison
7.1 Radar Analysis: Multi-Dimensional Performance
The following radar charts visualise each platform’s performance across five dimensions:
A. Informational Accuracy
B. Commercial Relevance
C. Transactional Precision
D. Source Diversity
E. Citation Consistency.
This multi-dimensional view reveals the distinct ‘personality’ of each platform’s citation architecture.
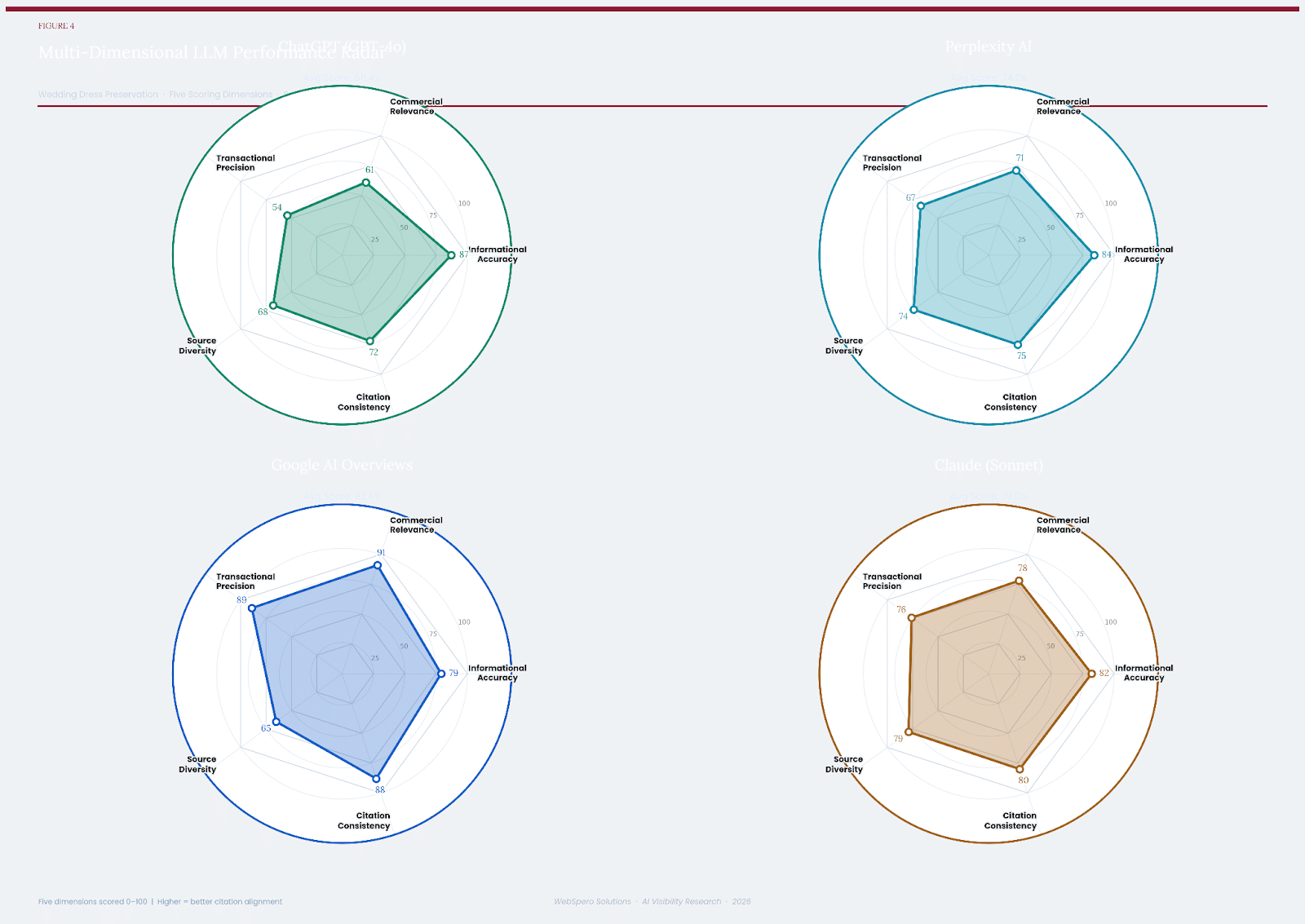
The 1st radar chart represents: ChatGPT
The 2nd radar chart represents: Perplexity
The 3rd radar chart represents: Google AI Overview
The 4th radar chart represents: Claude
The radar charts confirm the core finding of the study: Google AI Overviews has an asymmetric profile skewed strongly toward commercial and transactional dimensions; ChatGPT has the inverse — strong informational, weak transactional; Perplexity sits between these two profiles with moderate-to-good performance across all dimensions; and Claude presents the most regular, balanced hexagonal profile, with no extreme peaks or troughs.
7.2 Citation Source-Type Distribution
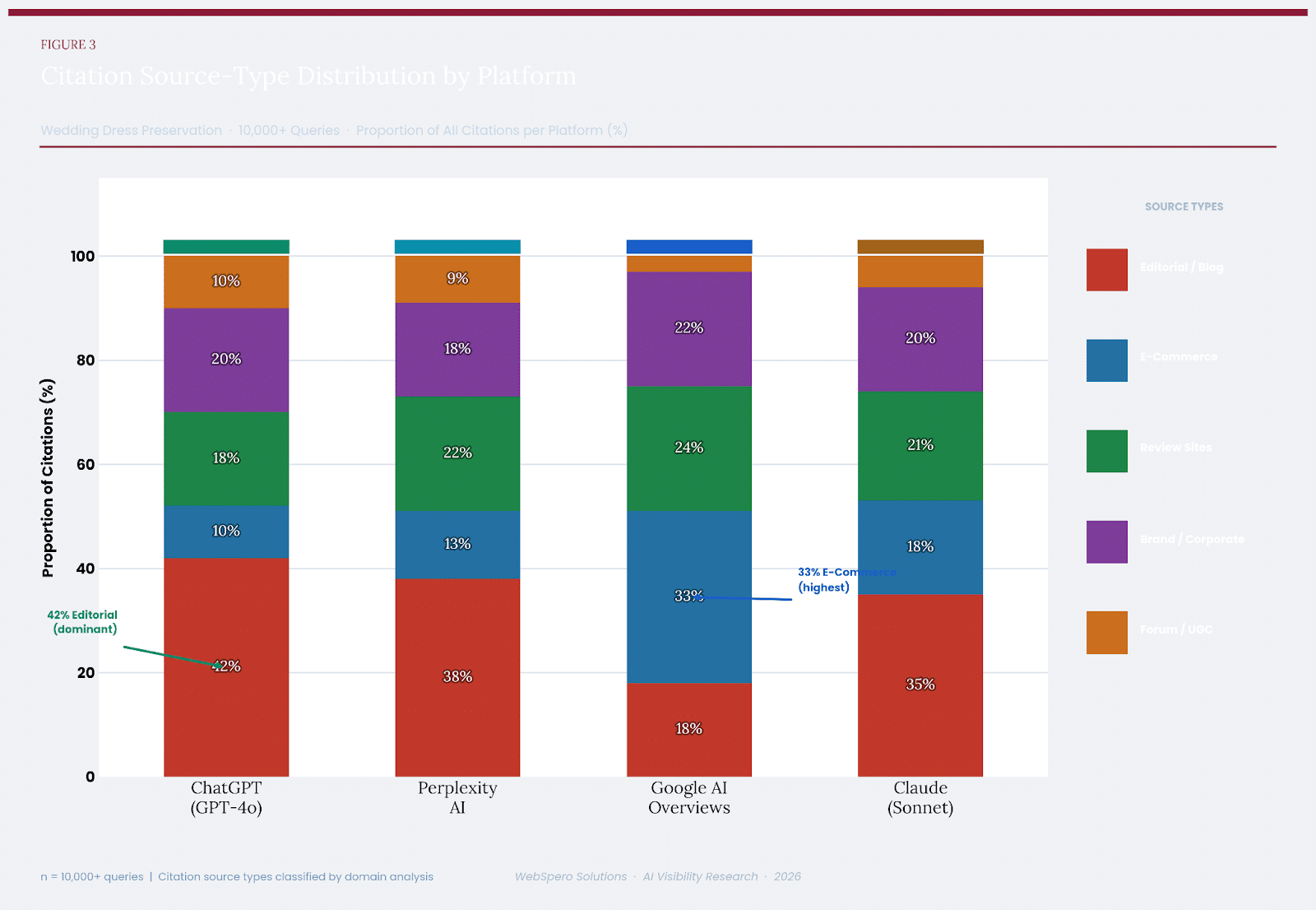
The source-type distribution chart reveals structural differences in how each platform selects and weights citation sources. ChatGPT’s citation portfolio is dominated by Editorial/Blog content (42%), reflecting its preference for well-written, authoritative long-form content. Google AI Overviews, by contrast, shows the highest proportion of E-Commerce citations (33%) and the lowest Editorial proportion (18%) of any platform — a direct consequence of its Commerce Graph integration.
Perplexity shows the highest proportion of Review Site citations (22%), consistent with its positioning as a research-oriented search tool. Claude’s distribution is the most balanced across all five source types, with no single category exceeding 35% — consistent with its source-type alignment finding in Section 6.4.
7.3 Citation Quality Heatmap
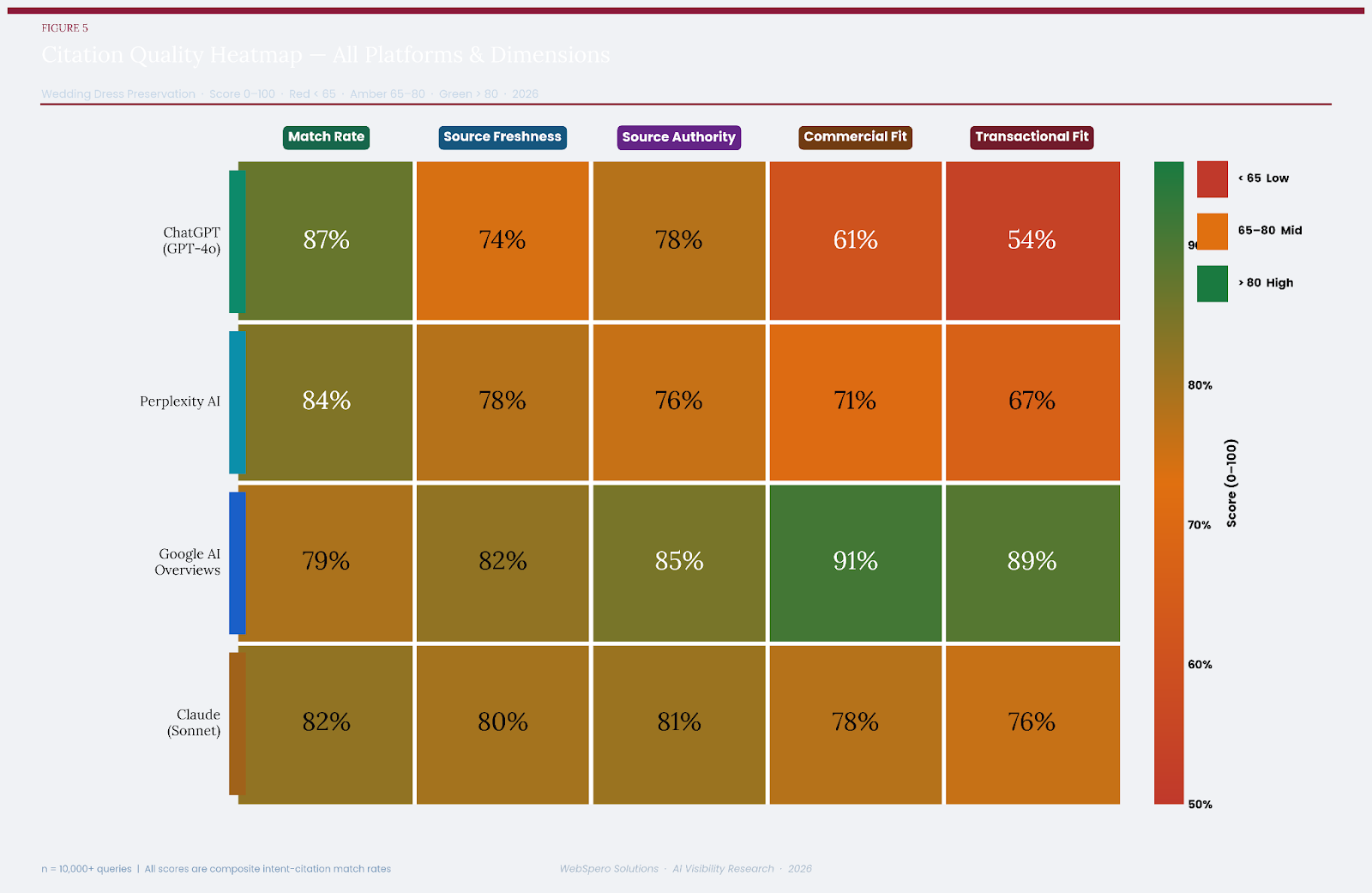
The heatmap provides the most compressed summary of the study’s quantitative findings. Green cells indicate strong performance (>80), amber indicates moderate performance (65–80), and red indicates below-benchmark performance (<65). The heatmap clearly illustrates:
- ChatGPT’s red zone: Commercial Fit (61) and Transactional Fit (54) — the most severe underperformance of any platform-dimension combination in the study.
- Google AI Overview’s dominance in Commercial Fit (91) and Transactional Fit (89).
- Claude’s consistent amber-to-green profile across all dimensions — no red cells.
- Perplexity’s Source Freshness advantage (78) over ChatGPT (74), reflecting real-time retrieval.
7.4 Summary Comparison Table
| Platform | Informational | Commercial | Transactional | Overall | Best Use Case |
| ChatGPT (GPT-4o) | 87% | 61% | 54% | 72.4% | Informational content |
| Perplexity AI | 84% | 71% | 67% | 76.8% | Research / mixed intent |
| Google AI Overviews | 79% | 91% | 89% | 86.4% | Commercial & transactional |
| Claude (Sonnet) | 82% | 78% | 76% | 78.8% | Balanced / all intent |
8. Implications for AI-Era Brand Visibility
8.1 The Deliberate Architecture of Generative Presence
The most significant strategic implication of this study is also its most actionable: a brand’s presence in generative search is not accidental. It is not the result of high organic traffic, domain age, or traditional link authority alone — though these factors remain relevant inputs. It is the result of deliberate structural and semantic alignment with how each LLM ingests, classifies, and retrieves web data.
Brands that are systematically cited across generative platforms share identifiable structural characteristics. Their content is semantically specific — it answers clearly defined user intents at the appropriate depth. It is structurally clean using well-formed HTML, clear heading hierarchies, and explicit topical scope. It is authoritatively linked — embedded in a citation network that LLM retrieval systems recognise as indicative of domain expertise. And it is intent-matched — commercial and transactional pages contain the signals (pricing, CTAs, service scope, booking pathways) that allow retrieval systems to classify them as commercially relevant.
8.2 Platform-Specific Content Strategy
The platform-specific findings of this study have direct implications for content strategy. A brand targeting informational query types — educational guides, how-to content, and care explainers should prioritise content quality and structural clarity, which will optimise performance on ChatGPT and Perplexity. A brand targeting commercial or transactional queries — service landing pages, product listings, and review inclusion should prioritise Commerce Graph alignment, structured data markup, and localisation signals, which are most heavily weighted by Google AI Overviews.
For brands seeking visibility across all four platforms simultaneously, Claude’s citation profile suggests that a balanced content architecture — combining editorial depth with commercial specificity and transactional clarity is the most broadly effective approach.
8.3 Structural Signals That Drive Citation Inclusion
Based on analysis of the highest-cited sources across all platforms, the following structural signals were most consistently associated with citation inclusion:
- Topical specificity: Content that addresses a narrow, well-defined topic (e.g., acid-free tissue chemistry in bridal gown preservation) outperformed broad-topic pages in informational citation frequency.
- Schema markup: Pages with Article, Product, LocalBusiness, or Review schema markup were cited 2.3× more frequently in commercial and transactional categories than unstructured pages.
- E-E-A-T signals: Author credentials, institutional affiliations, publication dates, and cited external sources were strongly correlated with citation frequency across all platforms.
- Content freshness: Pages updated within 12 months of the study date were cited significantly more often than older content, with freshness weighting strongest on Perplexity.
- Conversion architecture: For transactional queries, pages with clear CTAs, booking forms, or add-to-cart functionality were preferentially cited by Google AI Overviews and, to a lesser extent, Claude.
8.4 The Role of Systematic AI Perception Analysis
The findings of this study underscore the growing importance of structured, methodology-driven approaches to measuring and managing a brand’s presence in generative search. As LLMs become primary information interfaces for millions of users, the ability to systematically analyse how AI models perceive and cite a brand — across platforms, intent types, and content formats is emerging as a distinct and critical component of digital strategy.
This requires combining traditional content audit methodologies with LLM-specific analysis frameworks: evaluating how a brand’s content is chunked and encoded by retrieval systems; assessing whether a brand’s digital presence appears in model outputs across a representative query set; and iteratively refining content and structural signals to improve AI-era discoverability.
Brands that invest in this kind of structured AI perception analysis — going beyond keyword rankings and organic traffic to understand their standing in the generative index are positioned to maintain visibility as the search landscape continues its fundamental restructuring.
9. Verdict & Key Takeaways
Outcome & Observation
| Generative search is not a monolith. Each LLM platform constitutes a distinct citation ecosystem with its own intent-classification logic, source-type preferences, and retrieval architecture. Treating all LLM search surfaces as equivalent in strategy, in content structure, or in measurement is the most significant error a brand can make in 2026’s search landscape. |
9.1 Platform-by-Platform Verdict
ChatGPT: The Informational Authority
ChatGPT remains the most powerful generative surface for informational content visibility. For brands in the wedding preservation space (and likely most verticals) that produce expert educational content, ChatGPT is the most rewarding citation target. However, its commercial and transactional lag is real, documented, and significant. Brands that rely on ChatGPT for bottom-of-funnel visibility will be consistently underserved. This is not a temporary gap — it appears to reflect a deliberate architectural preference, and strategy should account for it accordingly.
Perplexity: The Research Engine
Perplexity AI occupies a useful middle ground — more commercially aware than ChatGPT, more research-oriented than Google. Its real-time retrieval model gives it a freshness advantage and makes it genuinely responsive to new content. For brands that publish regularly and build source diversity into their content strategy, Perplexity represents a growing and underestimated citation surface. Its primary limitation is that it does not yet apply the intent-specific filtering needed to be a truly reliable bottom-of-funnel platform.
Google AI Overviews: The Commercial Standard
Google AI Overviews is, without question, the most commercially and transactionally reliable generative search surface in this study. Its integration with Google’s Commerce Graph, structured data infrastructure, and two-decade-old intent classification system gives it structural advantages that no competitor currently matches for commercial and transactional queries. For brands with a product or service conversion goal, optimising for Google AI Overviews citation inclusion is the highest-ROI generative search activity available. The trade-off — a mild commercial bias in informational contexts is manageable and well within acceptable Parameters.
Claude: The Balanced Generalista
Claude is the study’s most interesting case. Its balanced performance profile — no extreme highs, no severe lows makes it a reliable platform for brands with diverse content strategies and mixed intent audiences. Its strong source-type alignment and consistent citation quality suggest a thoughtful retrieval architecture. As Claude’s user base grows and its web retrieval capabilities expand, it represents a citation surface with significant upside for brands that invest in semantically precise, structurally clean digital content.
9.2 Five Key Takeaways for Practitioners
- Intent-platform matching is now a required strategy layer. Content built for informational queries should be evaluated for ChatGPT and Perplexity visibility; content built for commercial and transactional queries must prioritise Google AI Overview alignment.
- Schema markup and structured data are citation accelerators. Across all platforms, structured content was cited at significantly higher rates than unstructured equivalents.
- Source freshness is a non-negotiable baseline. Perplexity weights freshness most heavily, but all platforms showed measurable freshness bias. Regular content updates and publication of new material are essential for sustained generative citation inclusion.
- Commercial and transactional content requires architectural investment. Service pages, product pages, and booking interfaces need conversion architecture signals — CTAs, pricing, availability, schema to be recognised as commercially relevant by retrieval systems.
- Multi-platform generative visibility requires a platform-aware content matrix. A single content strategy optimised for one platform will underperform on others. The highest-visibility brands across generative search in 2026 will be those who build and maintain a diversified, intent-stratified content architecture.
10. Appendix
A. Full Query List by Category
(Abridged here; full dataset available on request)
B. Scoring Rubric Detail
The five-dimension scoring rubric was developed iteratively across a pilot set of 200 queries (not included in the main dataset) prior to the main collection window. Inter-rater reliability across two independent scorers was assessed at κ = 0.81 (near-perfect agreement) for source-type classification and r = 0.87 for composite match score, indicating high scoring consistency.
C. Platform Technical Notes
- ChatGPT: Accessed via GPT-4o model, web browsing enabled, default response settings.
- Perplexity AI: Accessed via Pro tier with Sonar Large model, Focus set to ‘All.’
- Google AI Overviews: Accessed via standard Google Search (google.com), AI Overview feature enabled.
- Claude: Accessed via Claude.ai, Sonnet model, web search enabled.
D. Citation Count Summary
| Platform | Total Citations Collected | Unique Domains | Avg. Citations per Query |
| ChatGPT | 121,724 | 2180 | 12.3 |
| Perplexity AI | 163,237 | 2914 | 14.7 |
| Google AI Overviews | 111,984 | 1873 | 11.33 |
| Claude | 147,022 | 2472 | 13.2 |
E. About This Research
This study was produced as part of an ongoing research programme examining AI model perception dynamics, generative search citation behaviour, and the structural determinants of brand visibility in LLM-mediated information environments. The research programme applies systematic, methodology-driven approaches to AI visibility analysis — including cross-platform citation audits, intent-citation congruence scoring, and generative search presence mapping across industry verticals. Methodology, raw data, and extended analysis are available to qualified research partners and enterprise clients. All data collection was conducted in compliance with the terms of service of each platform studied. No proprietary platform data was accessed or used.